Abstract
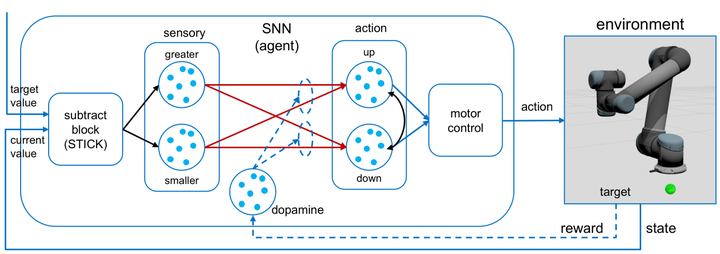
The main purpose of the human arm is to reach a target and perform a manipulation task. Human babies learn to move their arms by imitating and doing motor babbling through trial and error. This learning is believed to result from changes in synaptic efficacy triggered by complex mechanisms involving neuromodulators in which dopamine plays a key role. After learning, humans are able to reuse and adapt the motions without performing complex calculations. In contrast, classical robotics achieve target reaching by mathematically computing each time the inverse kinematics of the joint angles leading to a particular target, then validating the configuration and generating a trajectory. This process is computational intensive and becomes more complex with the amount of degrees of freedom. In this work, we propose a spiking neural network architecture to learn target reaching motions with a robotic arm using reinforcement learning, which is closely related to the way babies learn. To make our approach scalable, we sub- divide the kinematics structure of the robot and create one sub-network per joint. We generate training data offline by generating random reaching motions with an inverse kinematics calculation outside of the network. After learning, the inverse kinematics is no longer required, and the model is implicitly learned in the weights of the network. Mimicking the learning mechanisms of the brain, the synaptic plasticity learning rule is STDP modulated by dopamine, representing a reward. The approach is evaluated with a simulated Universal Robot UR5 with six degrees of freedom. The network successfully learns to reach multiple targets and by changing the reward function on-the-fly it is able to learn different control functions. With a standard computer our network was able to control a robotic kinematics chain up to 13 degrees of freedom in real time. We believe that model free motion controllers inspired on the human brain mechanisms can improve the way robots are programmed by making the process more adaptive and flexible.